|


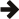
This section documents the following list of the command line options in more detail:
--hpx:bind
This command line option allows one to specify the required affinity
of the HPX worker threads to the underlying processing
units. As a result the worker threads will run only on the processing
units identified by the corresponding bind specification. The affinity
settings are to be specified using --hpx:bind=<BINDINGS>,
where <BINDINGS> have to be formatted as described
below.
![[Note]](../../../../images/note.png) |
Note |
|---|---|
This command line option is only available if HPX was built with support for HWLOC (Portable Hardware Locality (HWLOC)) enabled. Please see CMake Variables used to configure HPX for more details on how to enable support for HWLOC in HPX. |
The specified affinities refer to specific regions within a machine hardware topology. In order to understand the hardware topology of a particular machine it may be useful to run the lstopo tool which is part of Portable Hardware Locality (HWLOC) to see the reported topology tree. Seeing and understanding a topology tree will definitely help in understanding the concepts that are discussed below.
Affinities can be specified using HWLOC (Portable
Hardware Locality (HWLOC)) tuples. Tuples of HWLOC objects
and associated indexes can be specified in the form
object:index, object:index-index,
or object:index,...,index. HWLOC objects represent types
of mapped items in a topology tree. Possible values for objects are
socket, numanode, core,
and pu (processing unit).
Indexes are non-negative integers that specify a unique physical object
in a topology tree using its logical sequence number.
Chaining multiple tuples together in the more general form object1:index1[.object2:index2[...]]
is permissible. While the first tuple's object may appear anywhere in
the topology, the Nth tuple's object must have a shallower topology depth
than the (N+1)th tuple's object. Put simply: as you move right in a tuple
chain, objects must go deeper in the topology tree. Indexes specified
in chained tuples are relative to the scope of the parent object. For
example, socket:0.core:1 refers
to the second core in the first socket (all indices are zero based).
Multiple affinities can be specified using several --hpx:bind command line options or by appending
several affinities separated by a ';'.
By default, if multiple affinities are specified, they are added.
"all" is a special affinity consisting in the
entire current topology.
|
Note |
|---|---|
All 'names' in an affinity specification, such as |
Here is a full grammar describing the possible format of mappings:
mappings:
distribution
mapping(;mapping)*
distribution:
'compact'
'scatter
'balanced'
mapping:
thread-spec=pu-specs
thread-spec:
'thread':range-specs
pu-specs:
pu-spec(.pu-spec)*
pu-spec:
type:range-specs
~pu-spec
range-specs:
range-spec(,range-spec)*
range-spec:
int
int-int
'all'
type:
'socket' | 'numanode'
'core'
'pu'
The following example assumes a system with at least 4 cores, where each core has more than 1 processing unit (hardware threads). Running hello_world with 4 OS-threads (on 4 processing units), where each of those threads is bound to the first processing unit of each of the cores, can be achieved by invoking:
hello_world -t4 --hpx:bind=thread:0-3=core:0-3.pu:0
Here thread:0-3 specifies the OS threads for which to define
affinity bindings, and core:0-3.pu:0 defines that for each
of the cores (core:0-3) only their first processing unit
(pu:0) should be used.
|
Note |
|---|---|
|
The command line option hello_world -t4 --hpx:bind=thread:0-3=core:0-3.pu:0 --hpx:print-bind will cause this output to be printed: 0: PU L#0(P#0), Core L#0, Socket L#0, Node L#0(P#0) 1: PU L#2(P#2), Core L#1, Socket L#0, Node L#0(P#0) 2: PU L#4(P#4), Core L#2, Socket L#0, Node L#0(P#0) 3: PU L#6(P#6), Core L#3, Socket L#0, Node L#0(P#0) where each bit in the bitmasks corresponds to a processing unit the listed worker thread will be bound to run on. |
The difference between the three possible predefined distribution schemes
(compact, scatter, and balanced)
is best explained with an example. Imagine that we have a system with
4 cores and 4 hardware threads per core. If we place 8 threads the assignments
produced by the compact,
scatter, and balanced types are shown in eh figure
below. Notice that compact
does not fully utilize all the cores in the system. For this reason it
is recommended that applications are run using the scatter
or balanced options in
most cases.